Drzewa kategoryzacji
Drzewa kategoryzacji pozwalają na strukturyzację list obiektów w oparciu wartości ich metadanych oraz danych strukturalnych zawartych w powiązanych formularzach. Obok uporządkowanych i filtrowanych list obiektów drzewa kategoryzacji są wykorzystywane jako szablony dynamicznej selekcji podzbiorów obiektów w ramach zdefiniowanego dla nich kontekstu. Modele drzew kategoryzacji są tworzone przez upoważnionych użytkowników i zapisywane w ramach definicji ontologii systemu tworzonej w produkcie docuRob®Ontology Manager.
Rysunek 1 prezentuje rozwiniętą strukturę drzewa kategoryzacji „Dokumenty wg roku, miesiąca i typu” utworzoną w kontekście procesu pracy grupowej.
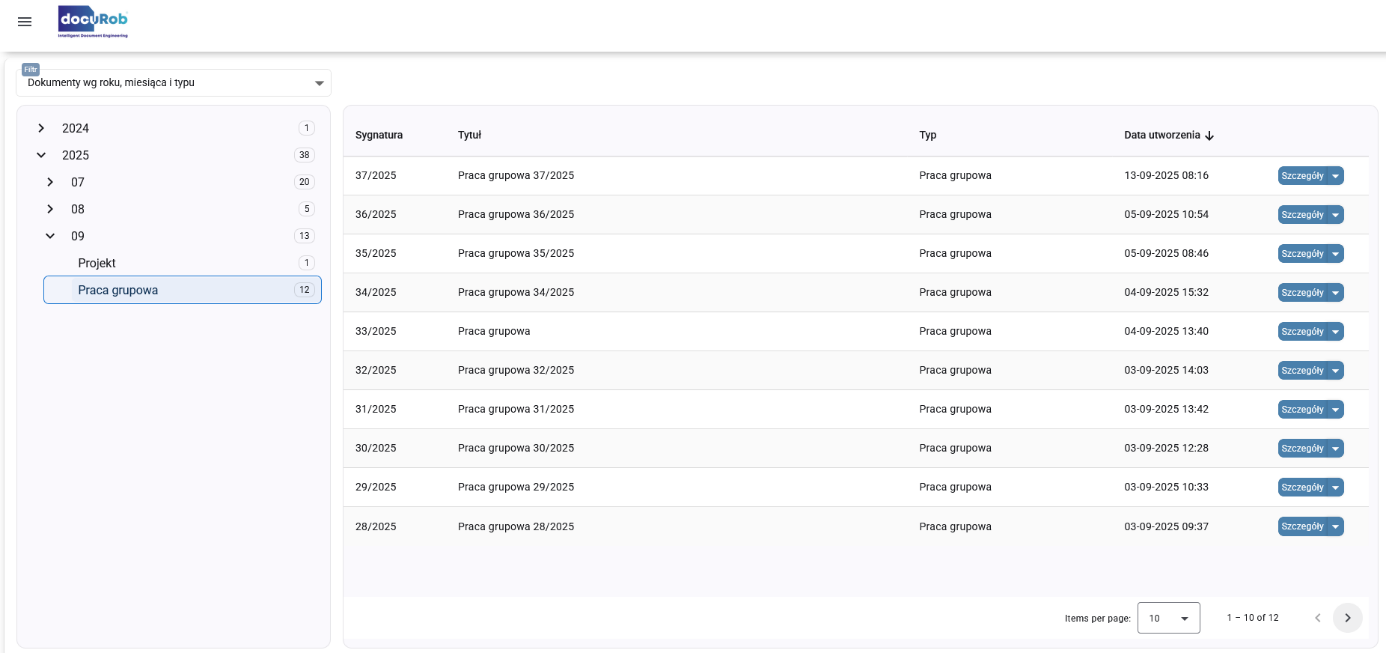
Rysunek 1. Rozwinięte drzewo kategoryzacji
Poziom 0
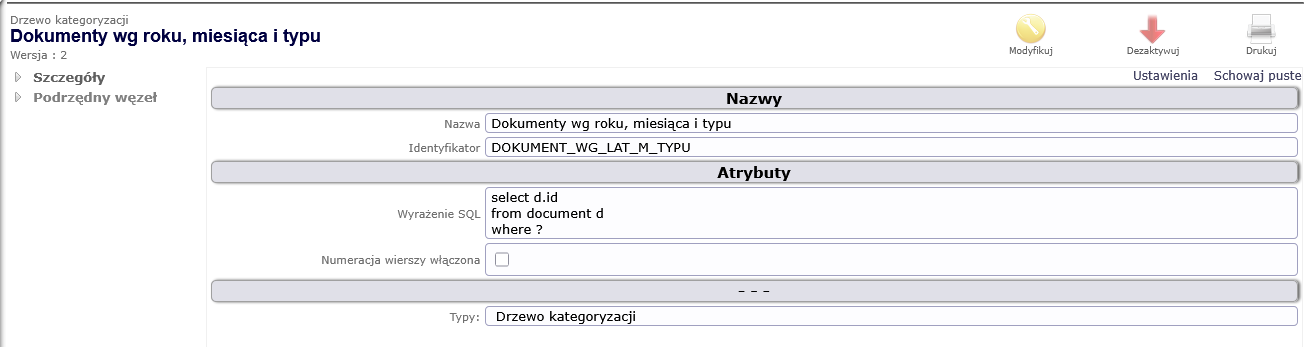
Rysunek 2. Definicja zapytania generującego podzbiór identyfikatorów obiektów
Zapytanie poziomu 0 generuje listę identyfikatorów obiektów wybierając ich podzbiór spełniający kryteria selekcji wyznaczane przez kolejne poziomy. To zapytanie zawsze występuje dla każdego typu drzewa kategoryzacji.
Węzły drzewa kategoryzacji są definiowane jako zapytania języka SQL obejmujące atrybuty metadanych obiektów oraz dane strukturalne tworzone jako wartości pól formularzy. W tym drugim przypadku wartości odpowiednich pól muszą być zapisywane jako atrybuty tabel relacyjnej bazy danych.
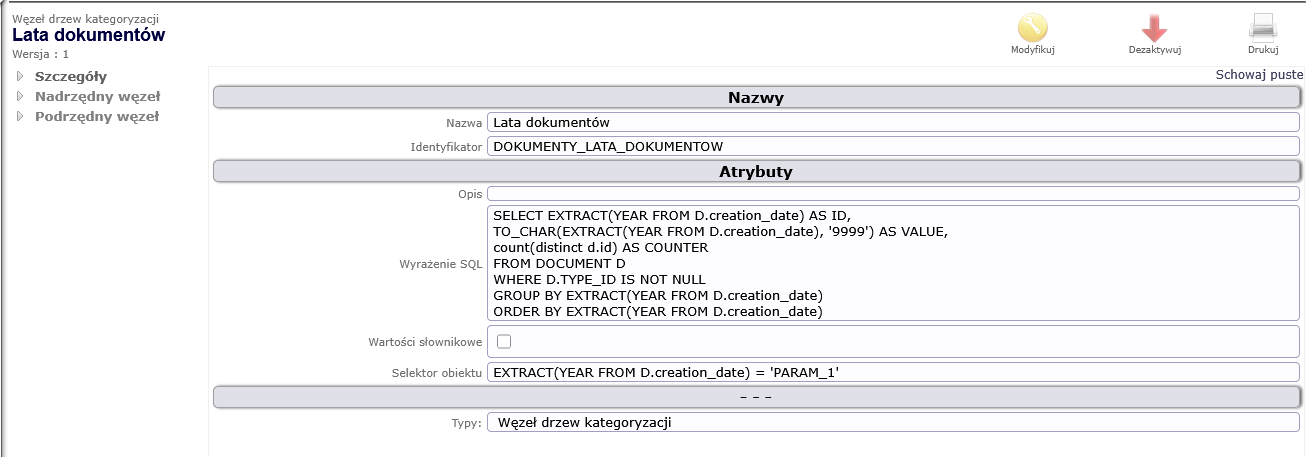
Rysunek 3. Definicja poziomu 1 drzewa kategoryzacji
Semantyka materializacji kolejnych poziomów drzewa kategoryzacji jest przedstawiona odpowiednio w kolejnych tabelach.
Liczba poziomów drzew kategoryzacji nie jest ograniczona a semantyka zapytań SQL zależy od modelowanego kontekstu wyszukiwania podzbioru obiektów. W ramach prezentowanego drzewa wykorzystano wyłącznie metadane obiektów.
Poziom 1
Ten fragment kodu SQL ma za zadanie zliczyć liczbę unikalnych dokumentów utworzonych w każdym roku, z wyłączeniem dokumentów, dla których nie określono TYPE_ID**.**
| Zapytanie | Wynik |
|---|---|
| SELECT EXTRACT(YEAR FROM D.creation_date) AS ID | Ta część wyodrębnia rok z kolumny creation_date z tabeli DOCUMENT (oznaczonej jako D) i przypisuje go do kolumny o nazwie ID. |
| TO_CHAR(EXTRACT(YEAR FROM D.creation_date), '9999') AS VALUE | Ta część również wyodrębnia rok z creation_date, ale następnie konwertuje go na czterocyfrowy ciąg znaków (np. „2023”) i przypisuje go do kolumny o nazwie VALUE. |
| count(distinct d.id) AS COUNTER | Ta część zlicza liczbę unikalnych identyfikatorów dokumentów (d.id) dla każdej grupy i przypisuje tę liczbę do kolumny o nazwie COUNTER. |
| FROM DOCUMENT D | Ta część określa, że zapytanie pobiera dane z tabeli DOCUMENT, która jest oznaczona jako D dla zwięzłości. |
| WHERE D.TYPE_ID IS NOT NULL | Ta część filtruje wyniki, aby uwzględnić tylko dokumenty, w których kolumna TYPE_ID ma wartość (tj. nie jest pusta). |
| GROUP BY EXTRACT(YEAR FROM D.creation_date) | Ta część grupuje wyniki według roku creation_date, dzięki czemu funkcja count(distinct d.id) zliczy unikalne dokumenty dla każdego roku. |
| ORDER BY EXTRACT(YEAR FROM D.creation_date) | Ta część sortuje końcowe wyniki w kolejności rosnącej na podstawie roku creation_date. |
Tabela 1. Semantyka materializacji poziomu 1 drzewa kategoryzacji
Powiązanie poszczególnych poziomów materializacji modelu drzewa kategoryzacji jest zarządzane przez strukturę danych i odpowiednie funkcje zarządzania ontologią systemu.
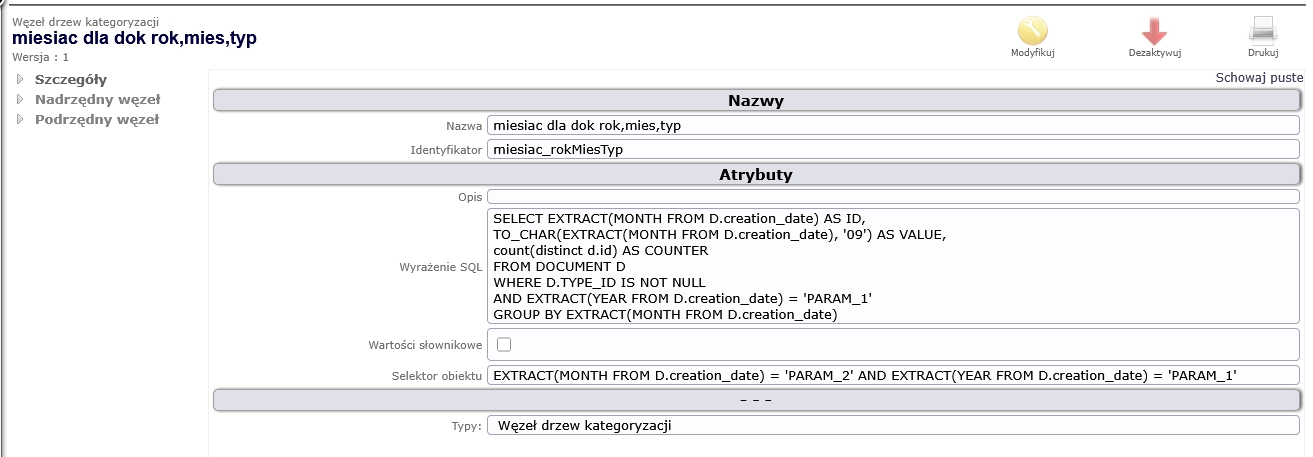
Rysunek 4. Definicja poziomu 2 drzewa kategoryzacji
Poziom 2
Ten fragment kodu SQL ma za zadanie zliczyć liczbę unikalnych dokumentów utworzonych w każdym roku, z wyłączeniem dokumentów, dla których nie określono TYPE_ID.
| Zapytanie | Wynik |
|---|---|
| SELECT EXTRACT(MONTH FROM D.creation_date) AS ID | Ta część wyodrębnia miesiąc z kolumny creation_date z tabeli DOCUMENT (oznaczonej jako D) i przypisuje go do kolumny o nazwie ID. |
| TO_CHAR(EXTRACT(MONTH FROM D.creation_date), '09') AS VALUE | Ta część również wyodrębnia miesiąc z creation_date, ale następnie konwertuje go na dwucyfrowy ciąg znaków z wiodącym zerem (np. „09” dla września) i przypisuje go do kolumny o nazwie VALUE |
| count(distinct d.id) AS COUNTER | Ta część zlicza liczbę unikalnych identyfikatorów dokumentów (d.id) dla każdej grupy i przypisuje tę liczbę do kolumny o nazwie COUNTER |
| FROM DOCUMENT D | Ta część określa, że zapytanie pobiera dane z tabeli DOCUMENT, która jest oznaczona jako D dla zwięzłości. |
| WHERE D.TYPE_ID IS NOT NULL | Ta część filtruje wyniki, aby uwzględnić tylko dokumenty, w których kolumna TYPE_ID ma wartość (tj. nie jest pusta). |
| AND EXTRACT(YEAR FROM D.creation_date) = 'PARAM_1' | Ta część dodatkowo filtruje wyniki, aby uwzględnić tylko dokumenty, których rok utworzenia (wyodrębniony z creation_date) jest równy wartości przekazanej jako 'PARAM_1' |
| GROUP BY EXTRACT(MONTH FROM D.creation_date) | Ta część grupuje wyniki według miesiąca creation_date, dzięki czemu funkcja count(distinct d.id) zliczy unikalne dokumenty dla każdego miesiąca. |
Tabela 2. Semantyka materializacji poziomu 2 drzewa kategoryzacji
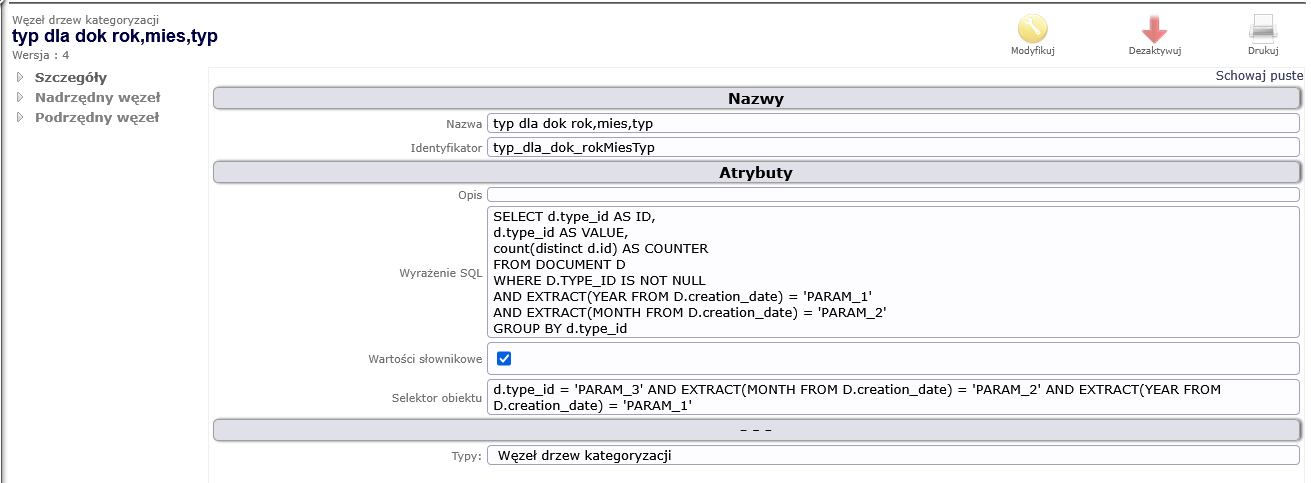
Rysunek 5. Definicja poziomu 3 drzewa kategoryzacji
Atrybut metadanych type_id występujący w ramach wszystkich typów obiektów musi być zdefiniowany w modelu repozytorium jako wartość słownikowa. Dodatkowe informacje dotyczące drzew kategoryzacji są zawarte w dokumentacji produktu docuRob®Ontology Manager.
Poziom 3
Ten fragment kodu SQL ma za zadanie zliczyć liczbę unikalnych dokumentów dla każdego typu dokumentu (type_id), w określonym roku i miesiącu, z wyłączeniem dokumentów, dla których nie określono TYPE_ID.
| Zapytanie | Wynik |
|---|---|
| SELECT d.type_id AS ID, | Ta część wybiera identyfikator typu dokumentu (type_id) z tabeli DOCUMENT (oznaczonej jako D) i przypisuje go do kolumny o nazwie ID. |
| d.type_id AS VALUE | Ta część ponownie wybiera identyfikator typu dokumentu (type_id) i przypisuje go do kolumny o nazwie VALUE. |
| count(distinct d.id) AS COUNTER | Ta część zlicza liczbę unikalnych identyfikatorów dokumentów (d.id) dla każdej grupy i przypisuje tę liczbę do kolumny o nazwie COUNTER. |
| FROM DOCUMENT D | Ta część określa, że zapytanie pobiera dane z tabeli DOCUMENT , która jest oznaczona jako D dla zwięzłości. |
| WHERE D.TYPE_ID IS NOT NULL | Ta część filtruje wyniki, aby uwzględnić tylko dokumenty, w których kolumna TYPE_ID ma wartość (tj. nie jest pusta). |
| AND EXTRACT(YEAR FROM D.creation_date) = 'PARAM_1' | Ta część dodatkowo filtruje wyniki, aby uwzględnić tylko dokumenty, których rok utworzenia (wyodrębniony z creation_date) jest równy wartości przekazanej jako 'PARAM_1'. |
| AND EXTRACT(MONTH FROM D.creation_date) = 'PARAM_2' | Ta część jeszcze bardziej filtruje wyniki, aby uwzględnić tylko dokumenty, których miesiąc utworzenia (wyodrębniony z creation_date) jest równy wartości przekazanej jako 'PARAM_2'. |
| GROUP BY d.type_id | Ta część grupuje wyniki według identyfikatora typu dokumentu (d.type_id), dzięki czemu funkcja count(distinct d.id) zliczy unikalne dokumenty dla każdego typu dokumentu. |
Tabela 3. Semantyka materializacji poziomu 3 drzewa kategoryzacji